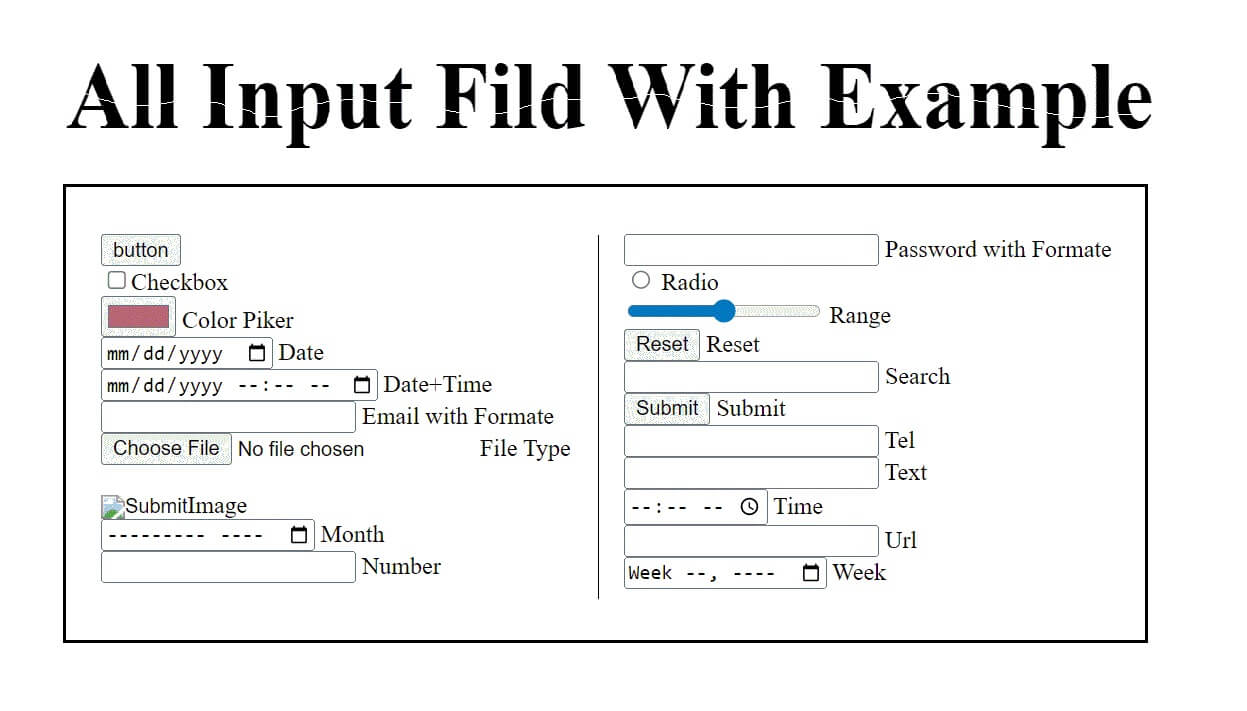

<!DOCTYPE html>
<html>
<head>
<title>Code karne do</title>
</head>
<body>
<h3>All Input Fild With Example</h3>
<input type="button" value="button"><br/>
<input type="checkbox">Checkbox<br/>
<input type="color"> Color Piker<br/>
<input type="date"> Date<br/>
<input type="datetime-local"> Date+Time<br/>
<input type="email"> Email with Formate<br/>
<input type="file">File Type<br/>
<input type="hidden"><br/>
<input type="image">Image<br/>
<input type="month"> Month <br/>
<input type="number"> Number<br/>
<input type="password"> Password with Formate<br/>
<input type="radio"> Radio<br/>
<input type="range"> Range<br/>
<input type="reset"> Reset<br/>
<input type="search"> Search<br/>
<input type="submit"> Submit<br/>
<input type="tel"> Tel<br/>
<input type="text"> Text<br/>
<input type="time"> Time<br/>
<input type="url"> Url<br/>
<input type="week"> Week<br/>
</body>
</html>